
Python is the most frequently used language as it is easy to understand. However, the term this interpreted code sometimes leads to performance bottleneck problems, which are generally encountered in applications needing a lot of computer power. Data pipelines, web services, and scientific simulations deal with optimizing Python code for performance, especially for fast processing, resource management, and ease of user interaction.
This post will delve into some actionable ways of supercharging Python code, from low-level to high-level architectural improvements.
What is Optimization?
Python code optimization enhances program code to consume fewer resources, run faster, or handle increased workloads better. It is not about smartness but about getting rid of unsatisfactory things. Optimization aims to find a spot between performance direction and maintainability so that the code is still readable and debuggable.
Why is Optimizing Python Code needed?
There are several performance issues in Python. In some cases, one needs to do extra coding while optimizing Python code because of the nature of the operations being performed. Let’s start with some everyday performance issues in Python to understand the need for optimization in the first place.
- Reduce the usage of CPU, memory, and I/O resources.
- Scalability: Handle growing workloads without proportional resource increases.
- User Experience: Faster responses in web apps, real-time analytics, or GUIs.
- Cost Optimization: Reduce spending on cloud resources based on optimizing resource usage.
Missing Techniques for Optimizing Python Code
Not every technique gets the attention it deserves. Here are a few recommendations that may not be on your radar:
1. Caching & Memoization
Use the in-built function called lru_cache from the functools module. This method helps to avoid redundant calculations. Since results are cached, your code is exempted from doing repeated work. This kind of approach can save time when it comes to repetitive tasks.

2. Cython
Cython allows you to compile Python to C. Compiled code executes faster. Using Cython means you can harness the speed of C for portions of your code. This method is beneficial when you have intensive numerical calculations to do.

3. Memory Optimization with slots
Custom classes that use slots use less memory. They do so by passing on the overhead of dict. This trick can be helpful when you want to create many objects quickly.

4. Avoid Unnecessary Imports
Every import has some overhead when your program starts. Import only what you need. This reduces memory and speeds up startup. Review which libraries are necessary and optimize your code. Tools like Vulture can identify dead code.

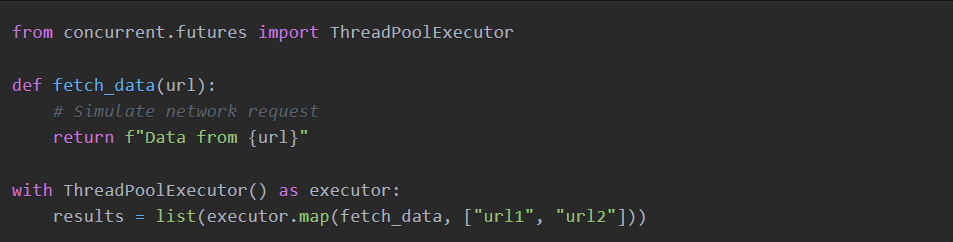
5. Concurrency & Parallelism
Python has built-in support for concurrency using modules such as concurrent.futures and asyncio. Overall, use these for I/O-bound tasks, except for the above. They allow you to perform many operations simultaneously, reducing waiting time and improving performance.
6. GPU Acceleration with CuPy
If you need numerical computing, you can use CuPy to benefit from GPUs in your code. However, processing data on a GPU can be significantly quicker than using a CPU, and it is super helpful when we do heavy calculations. Replace NumPy with CuPy for GPU-accelerated operations.

7. Dask for Big Data
Dask is a library for big data. It aids in parallel computation and lazy evaluation. Dask then breaks the work into smaller pieces and executes them effectively without consuming excessive memory.



